



九、数据库
1,概述、三级模式两级映像、数据库设计步骤
三级模式:
内模式(物理模式、存储模式。文件)
模式(概念模式、逻辑模式、模式。面向数据库的设计人员。表结构)
外模式(视图)
两级映像:
模式和内模式 物理独立性
外模式和模式 逻辑独立性
一个数据库可以有多个外模式,只有一个模式和内模式
数据库设计:
1需求分析--数据流图、数据字典、需求说明书。
2概念结构设计--得到ER图
ER图合并的时候会产生的三类冲突:

属性冲突 学生--姓名 学院--姓名 同一个属性类型不同,字符类型不同
命名冲突 同一个含义不同名字
结构冲突 同一个实体在不同对象里有不同的属性。1对多
3逻辑结构设计--将ER图变为关系模式(表)
4物理设计--存储结构
5数据库实施阶段--建库建表
6数据库运行和维护阶段
2,数据模型:
数据模型分为
1概念模型(ER图)
2关系模型(二维表形式的ER图) 元组(行) 属性(列)
3网状模型:形成一张网
4面向对象模型: 对象
数据库模型三要数:数据结构、数据操作、数据的约束条件
3,代数关系:
并(加法) 交(共有部分) 差(减法)A-B B-A不一样 被减数独有部分
笛卡尔积:S1XS2(全排列) (列名相加数据相乘)
投影:Π 选择要展示的列select
选择:σ 按条件选择某行where no=1
自然连接:(列名去重复相加,筛选共有元素相同的行保留)选择属性列并集的行 ABC ACD ---> ABCD
4,函数依赖
函数依赖:X-->Y X决定Y Y依赖X
两种规则:
部分函数依赖,传递函数依赖
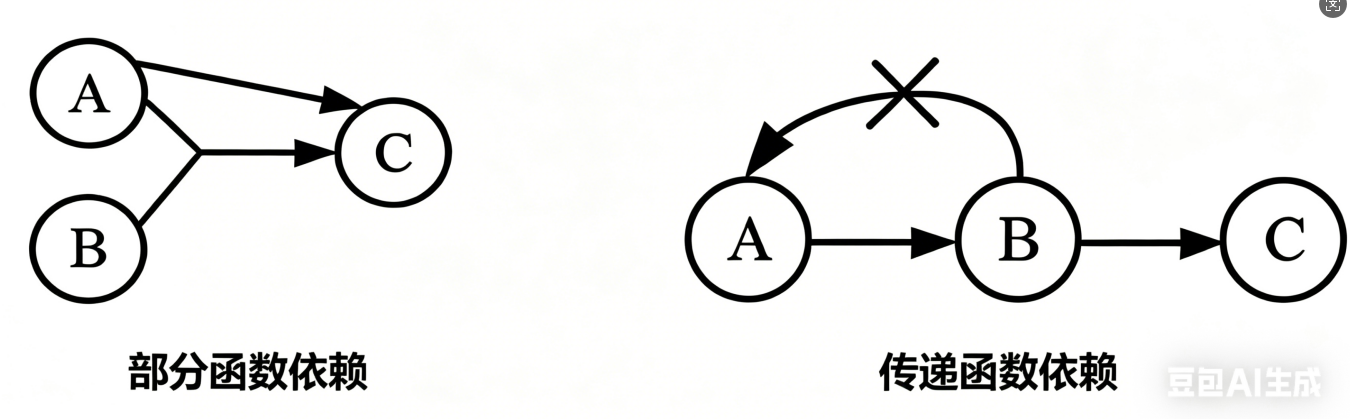
设关系模式R(U,F),其中U为属性集,F是U上的一组函数依赖。
函数依赖的公理系统:(阿姆斯特朗公理)
自反律:对于任意属性集合X和Y,有Y属于X,X属于U,则X→Y被F逻辑蕴含。也就是说如果属性集Y属于X,则X可以决定Y,又可以说属性集X可以决定他的属性子集。
增广律:对于任意属性集合X、Y和Z,如果X →Y,那么XZ →YZ
传递律:任意属性集合X、Y和Z,如果X →Y且Y →Z,那么X → Z。
可推导
合并律: 对于任意属性集合X、Y和Z,如果X →Y和X → Z,那么X →YZ
分解律:对于任意属性集合X、Y和Z,如果X→YZ,则X→Y和X→Z。
合成律:对于任意属性集合X、Y和Z,如果X →Y且Y →Z,那么XZ →YZ。
5,键
超键(码):唯一标识记录的属性集合
候选键:最小的超键去掉冗余
主属性:有代表意义的,不是有其他属性推导出来的属性。候选键的并集
主键: 候选键中选的一个属性或者属性集。
候选关键字:根据依赖集,从未出现过在右边,必然是候选键,然后看能遍历所有属性。只有出度没有入度
6,约束:
外键:是指一个表中的属性,它引用另一个表中的主键。外键用于建立表之间的关系。
实体完整性约束:即主键约束,主键值不能为空,也不能重复。
参照完整性约束:即外键约束,外键必须是其他表中已经存在的主键的值,或者为空。
用户自定义完整性约束:自定义表达式约束,如设定年龄属性的值必须在0到180之间。
7,范式
概念设计中ER模型转关系模型
1NF 不可以拆分出小表,不满足exel(无小表)
2NF 有联合主键 (联合主键 ) 每一个非主属性完全依赖于某一个候选键
3NF 有传递依赖 (每个列都和主键有关) 每一个非主属性不依赖于其他非主属性
BCNF 数据冗余,解决更新操作不正确的问题
8,反规范化
反规范化技术:规范化设计后,数据库设计者希望牺牲部分规范化来提高性能
具体方式:
1增加余列:在多个表中保留相同的列
2增加派生列:在表中增加可以由本表或其它表中数据计算生成的列。
3重新组表:把这两个表重新组成一个表来减少连接而提高性能。
4水平分割表:根据一列或多列数据的值,把数据放到多个独立的表。
5垂直分割表:对表进行分割,将主键与部分列放到一个表中
9,模式分解
有损连接:R1交R2>R1-R2或R2-R1
是否保持函数依赖分解:对于关系模式R,有依赖集F,若对R进行分解,分解出来的多个关系模式,保持原来的依赖集不变,则为保持函数依赖的分解。另外,注意要消除掉冗余依赖(如传递依赖)
有损无损分解:分解后的关系模式能够还原出原关系模式,就是无损分解,不能还原就是有损
是否保持函数依赖案例:设原关系模式R(A,B,C),依赖集F(A->B,B->C,A->C),将其分解为两个关系模式R1 (A,B)和R2(B,C),此时R1 中保持依赖A->B,R2保持依赖B->C,说明分解后的R1 和R2是保持函数依赖的分解,因为A->C这个函数依赖实际是一个冗余依赖,可以由前两个依赖传递得到,因此不需要管。
定理:如果R的分解为p={R1 ,R2},F为R所满足的函数依赖集合,分解p具有无损连接性的充分必要条件是R1∩R2->(R1 -R2)或者R1 ∩R2->(R2-R1 )。
10,并发控制和封锁协议
事务ACID特性:
操作原子性A:银行转账,要么全做要么全不做
数据一致性C:A减少,B就应该收到
执行隔离性I: 在提交之前对其他事务都不可见
改变持续性D: 结果改变是持续的
加锁是解决事务并发造成的更新丢失,读脏数据 数据复读。
X排它锁(写锁)不能加任何锁
S共享锁(读锁)只能加读锁
一级封锁协议:修改之前加X,解决丢失更新
二级封锁协议:一的基础上,读的时候加S,解决丢失更新,读脏数据
三级封锁协议:加X S
11,SQL语句包括:
DDL数据定义语言
DML数据操作语言
DQL数据查询语言
TCL事务控制语言
DCL数据控制语言
1数据定义语言(DDL):用于定义数据库对象,如表、视图、索引等。包括CREATE、ALTER、DROP等语句。
2数据操作语言(DML):用于对数据库中表的数据进行增删改操作。包括INSERT、UPDATE、DELETE等语句。
3数据查询语言(DQL):用于查询数据库中表的记录。主要是SELECT语句及其子句
排序order by,默认为升序(ASC),降序要加关键字DESC:select * from t1 order by sno
分页limit,limit startIndex,pageSize,startIndex代表从第几项开始,pageSize代表展示多少项数据,startIndex从0开始算:select * from t1 limit 0,1 0
分组查询group by,分组时要注意select后的列名要适应分组,having为分组查询附加条件:select sno,avg(score) from student group by sno having(avg(score)>60)
字符串匹配:like,%匹配多个字符串,_匹配任意一个字符串:select * from t1 where snamelike'a_'
4事务控制语言(TCL):用于管理数据库事务。包括COMMIT、ROLLBACK、SAVEPOINT等语句。
5数据控制语言(DCL):用于管理数据库的权限和安全性。主要是GRANT和REVOKE语句。
12,应用程序与数据库交互:
应用程序通过程序接口来访问数据库
包括
1 库函数级别访问接口 OCI
2 嵌入SQL访问接口
3 通用数据接口标准:为不同的数据库提供统一的接口(ODBC)
4 ORM访问接口:使用框架技术让对象和数据库中的表产生映射
ODBC--->JDBC
ORM访问接口:myBAtis,JPA,Hibernate
13,nosql非关系型数据库
NOSQL:非关系型数据库(易拓展、大数据、高性能、高可用、灵活的数据模型)不保证ACID
Nosql框架分层(从下到上):数据持久层、数据分布层、数据逻辑模型层、接口层
列式存储数据库:行列存储数据,分布式海量数据。HBase
键值对数据库:简单易部署Key-Value redis
文档型数据库:键值对升级版,允许嵌套 MongDb
图数据库:图形 Neo4J
NoSQL的特征:易拓展、大数据量、高性能、灵活的数据模型、高可用
NoSQL的框架分层(从下至上):数据持久层、数据分布层、数据逻辑模型层和接口层,层次之间相辅而成,协调工作。
NoSQL适用于哪些场景:数据模型比较简单、需要灵活性更强的系统、对数据性能要求高、不需要高度的数据一致性。
14,分布式一致性协议
2PC(两段提交协议):用于分布式事务中的一致性协议,通过协调者节点向各参与者发送提交指令,确保所有节点要么提交事务,要么回滚。但2PC存在阻塞和单点故障的问题,参与者在协调者故障时可能会长时间等待。
·3PC(三段提交协议):是2PC的增强版,增加了“预提交"阶段,旨在解决2PC中的阻塞问题。3PC通过分阶段确认参与者的状态,提高了容错性,避免了协调者故障时的长时间阻塞,但实现复杂性相对较高。
Paxos协议:经典的分布式一致性协议,但实现复杂,难以理解。
Raft协议:相比于Paxos协议,Raft协议的设计目标是简化理解和实现,专注于为分布式系统提供强一致性保障。Raft通过领导选举和日志复制的机制来保持数据一致性,确保系统在节点故障或网络分区时依然能够正常运行。Raft的核心思想是将复杂的分布式一致性问题分解为易于理解的子问题,易于实现且能够提供较高的容错性,广泛应用于现代分布式系统中,如Kubernetes和Consul。
CAP原则:又称之为CAP定理,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partitiontolerance(分区容错性),三者不可得兼。

评论交流
欢迎留下你的想法